
«Se ha detectado un nuevo problema de Cobertura del índice en…». Es un aviso que puedes haber recibido de Google, desde que se presentó la Nueva Search Console a principios de 2018.
Un nuevo diseño y nuevas funcionalidades (aún en fase beta), que se han lanzado con el objetivo de proporcionar más información a los propietarios de sitios web, sobre la clásica suite «Google Webmaster Tools». Ese plus de información acerca de cómo trata Google tu sitio web, que tanto demandamos los que nos dedicamos a esto del SEO.
Nada más acceder a la versión beta de esta nueva Search Console, te encontrarás una pantalla como esta:
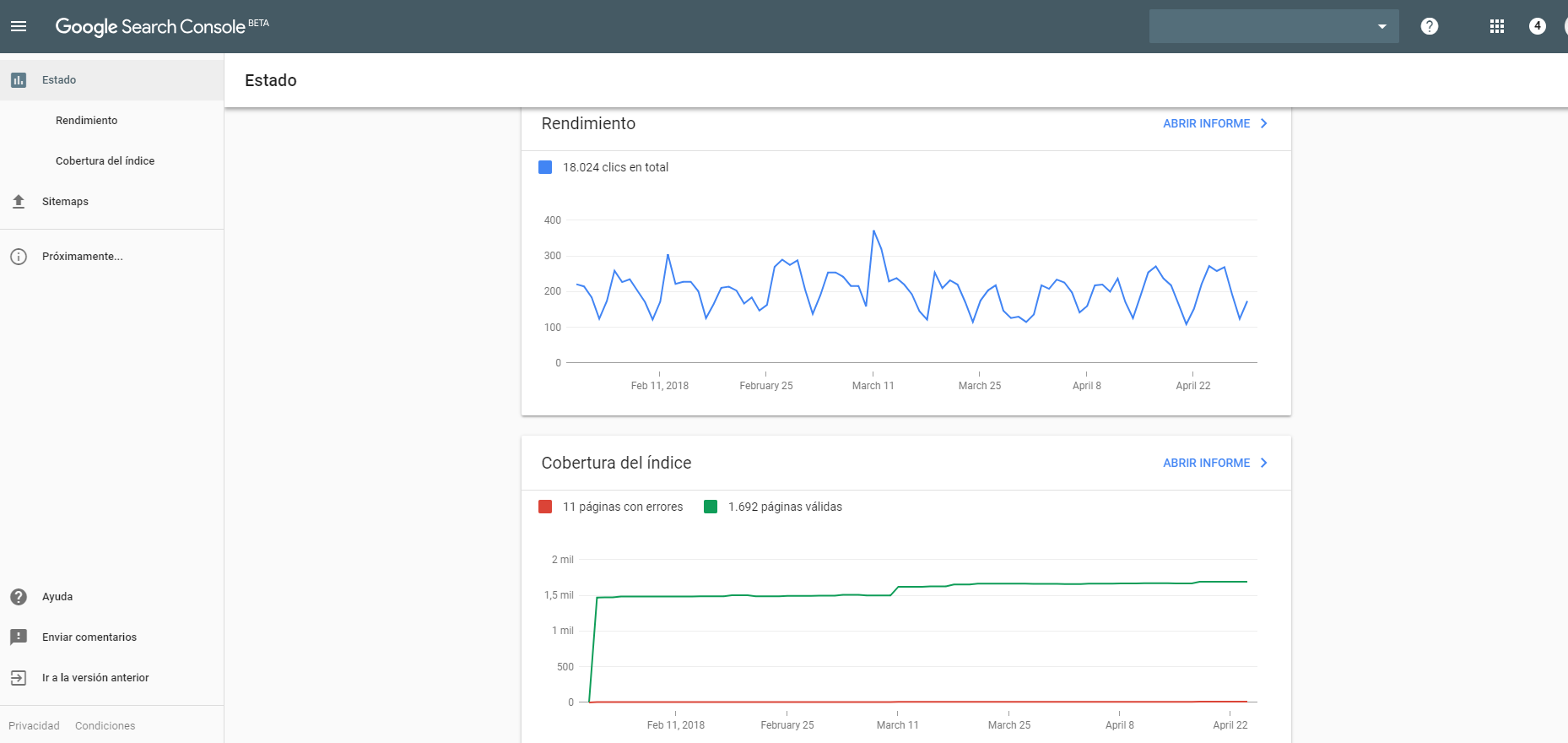
Donde de momento destacan los 2 tipos de informes que nos ofrece:
- Rendimiento
- Cobertura del índice
El informe de rendimiento nos muestra la tendencia en las búsquedas (impresiones, clics, ratio de clics y posición media). Básicamente la misma información que tienes en Google Search Console actualmente, en los informes de analítica de búsqueda.
Con la ventaja de que te muestra un espectro de información más amplio. Mientras que con la versión estable de esta herramienta tienes información de los últimos 3 meses, con la nueva actualización verás todo el histórico de datos (desde que estos son recogidos).
Pero en esta ocasión me interesa principalmente explicarte la llamada Cobertura del índice. Que es lo que nos trae de cabeza desde que se empezaron a migrar sitios a la nueva versión.
¿Qué es la cobertura del índice de tu sitio web?
Por rebuscada o rara que pueda parecer la palabrita, es información vital para posicionar tus páginas en los resultados de Google. Habla de las páginas que ha cubierto (rastreado) el robot de Google para construir su índice de contenidos que se utilizará para los rankings.
Con el informe de cobertura de índice de la nueva Search Console puedes ver qué páginas se han rastreado o intentando rastrear. De manera que puedes corregir posibles errores que impiden al robot de Google incluir determinadas páginas.
Para qué sirve el informe de Cobertura del índice
Pues sobre todo para 2 cuestiones:
- Para evitar que haya páginas que tú quieres que se indexen, pero no lo estén haciendo porque las has bloqueado en el archivo robots.txt.
- Para corregir las páginas a las que el robot está accediendo, pero en realidad no quieres que sea así porque no tienen objetivos SEO (ej. Sitemaps que envían páginas que no quieres posicionar).
Tipos de estados de la cobertura del índice
Nos encontramos 4 posibles estados con respecto a las páginas que la “araña” de Google se ha encontrado en el proceso de rastreo.
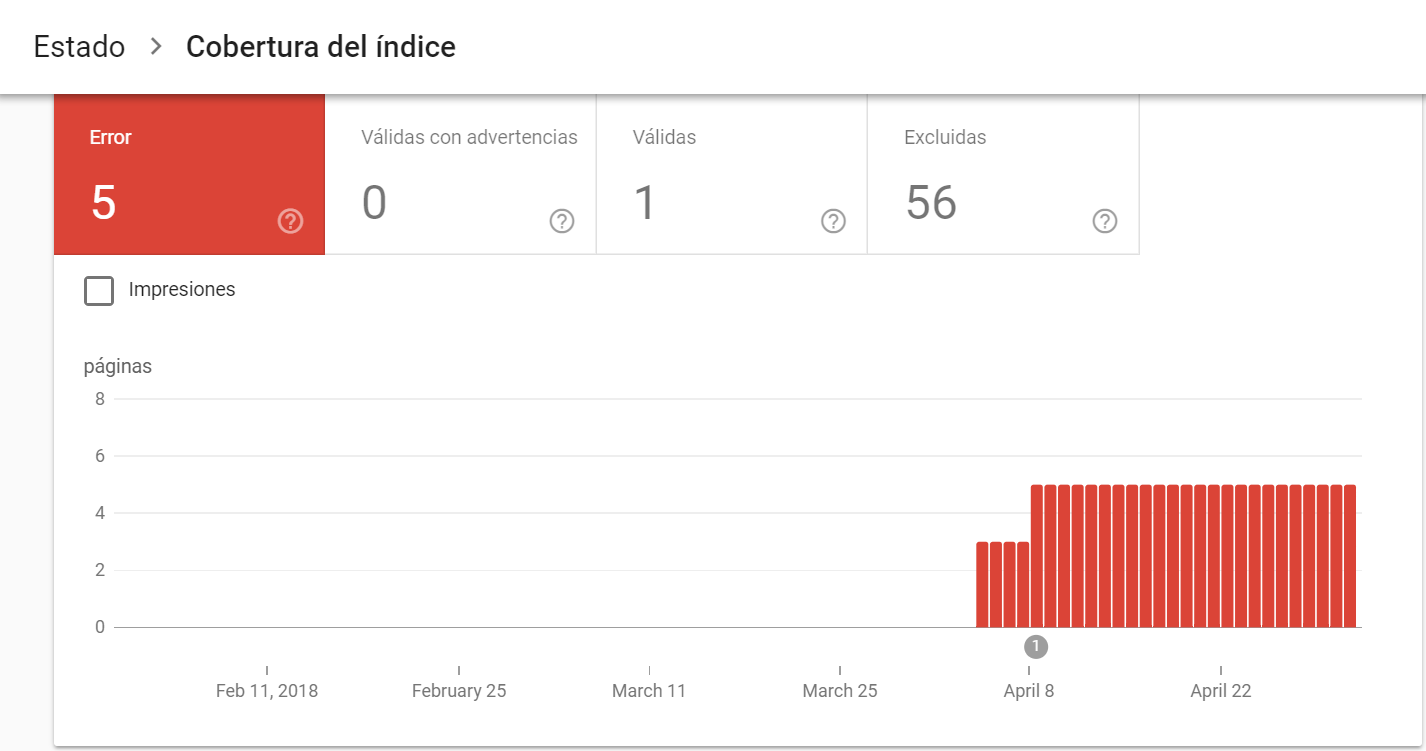
1. Error
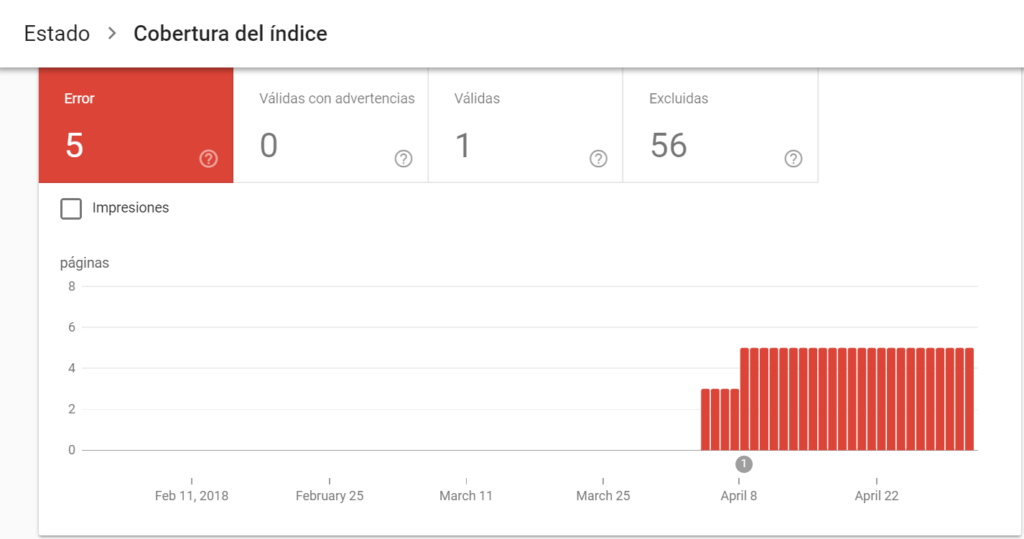
Páginas que no se han indexado porque el robot se ha encontrado con uno de los siguientes problemas:
- Error del servidor donde está alojada tu web.
- Se ha realizado una redirección de manera incorrecta.
- El archivo robots.txt ha bloqueado esa página a pesar de haberla enviado a indexar a través del Sitemap.
- La URL rastreada tiene la etiqueta Noindex.
- La página enviada devuelve un error Soft 404 (el servidor dice “OK, tengo esa página”, mientras el robot se encuentra con que no puede abrirla). Es posible que estés mostrando un contenido solo accesible para usuarios logueados, con lo que el robot no puede acceder a él.
- El robot no puede ser revisar la URL por un tema de seguridad.
- Dirección web que genera un error 404 (URL que no existe en el servidor).
- Página que tiene un problema de rastreo no englobado en el grupo anterior.
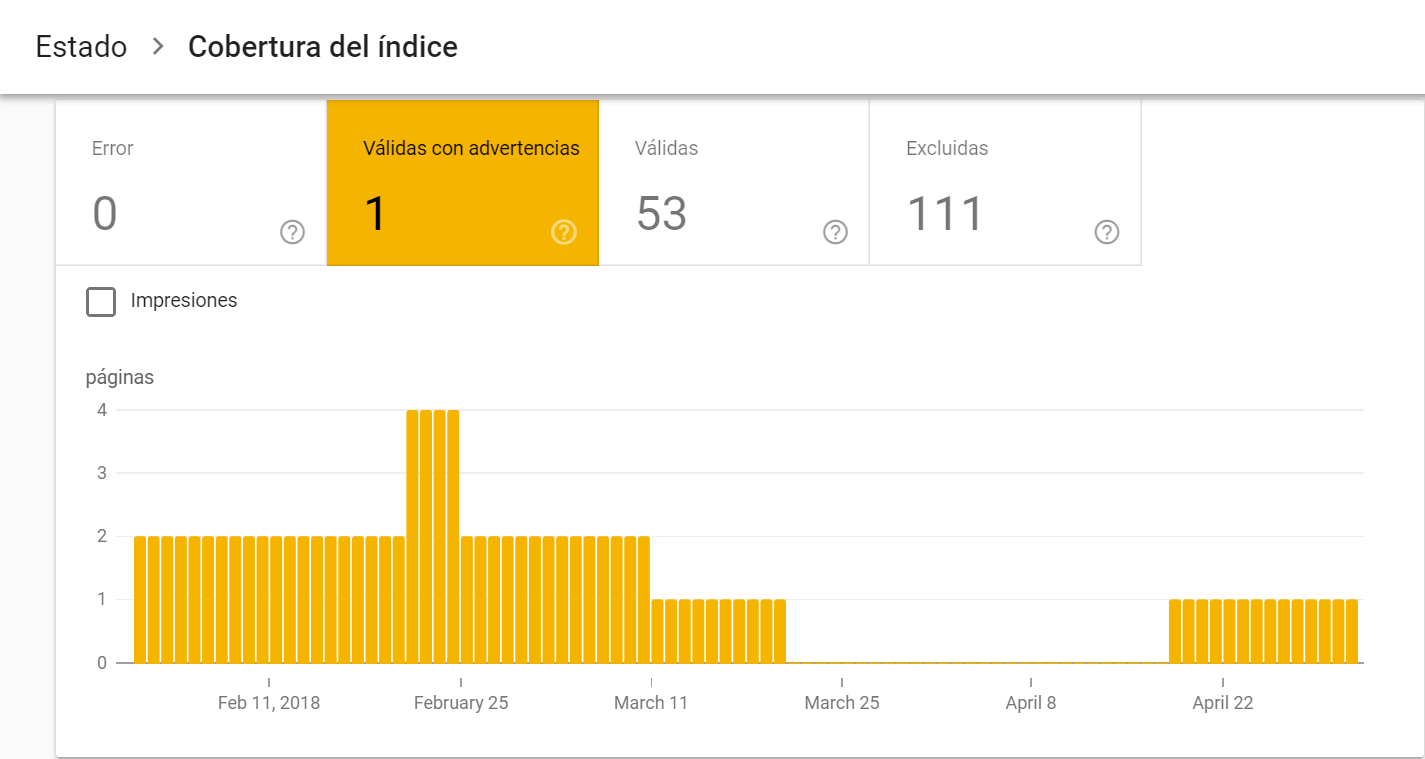
2. Válidas con advertencias
Son páginas que están o han estado indexadas, pero necesitan revisión porque algo está fallando. Normalmente son páginas que se han indexado (porque el robot ha seguido un enlace a ella) pero que están bloqueadas en robots.txt.
Lo que refleja una incompatibilidad entre lo que le decimos al Google por un lado (enlace a esta página, “rastréala e indexala”) y lo que le decimos por otro (“no entres en esta página”).
Esto es habitual cuando queremos que deje de mostrar un contenido en los resultados de búsqueda y escogemos la solución drástica de eliminarlo en el archivo Robots.txt. Google encuentra referencias a este contenido, ya sea en su índice o bien en el Sitemap de tu sitio o en enlaces dentro del propio sitio.
Si quieres que una página no se indexe pero que haya enlaces a ella para los usuarios, el mecanismo a utilizar no es el Robots.txt sino la directiva Noindex que te comentaba en el punto anterior.
3. Válidas
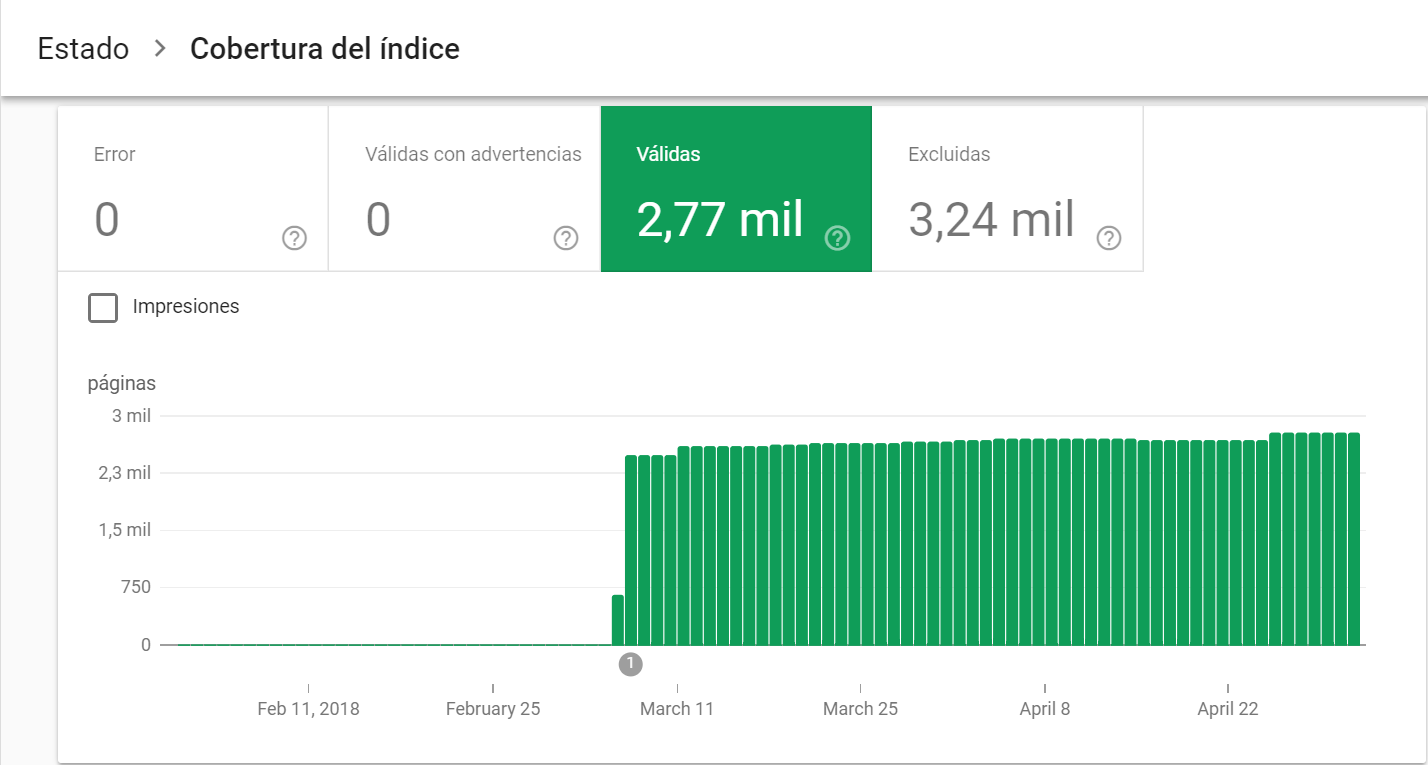
Páginas que se han indexado correctamente. Deberían coincidir con las páginas que quieres posicionar. Si no es así, revisa los enlaces internos y el Sitemap, para evitar que se desperdicie el “presupuesto de rastreo”.
4. Excluidas
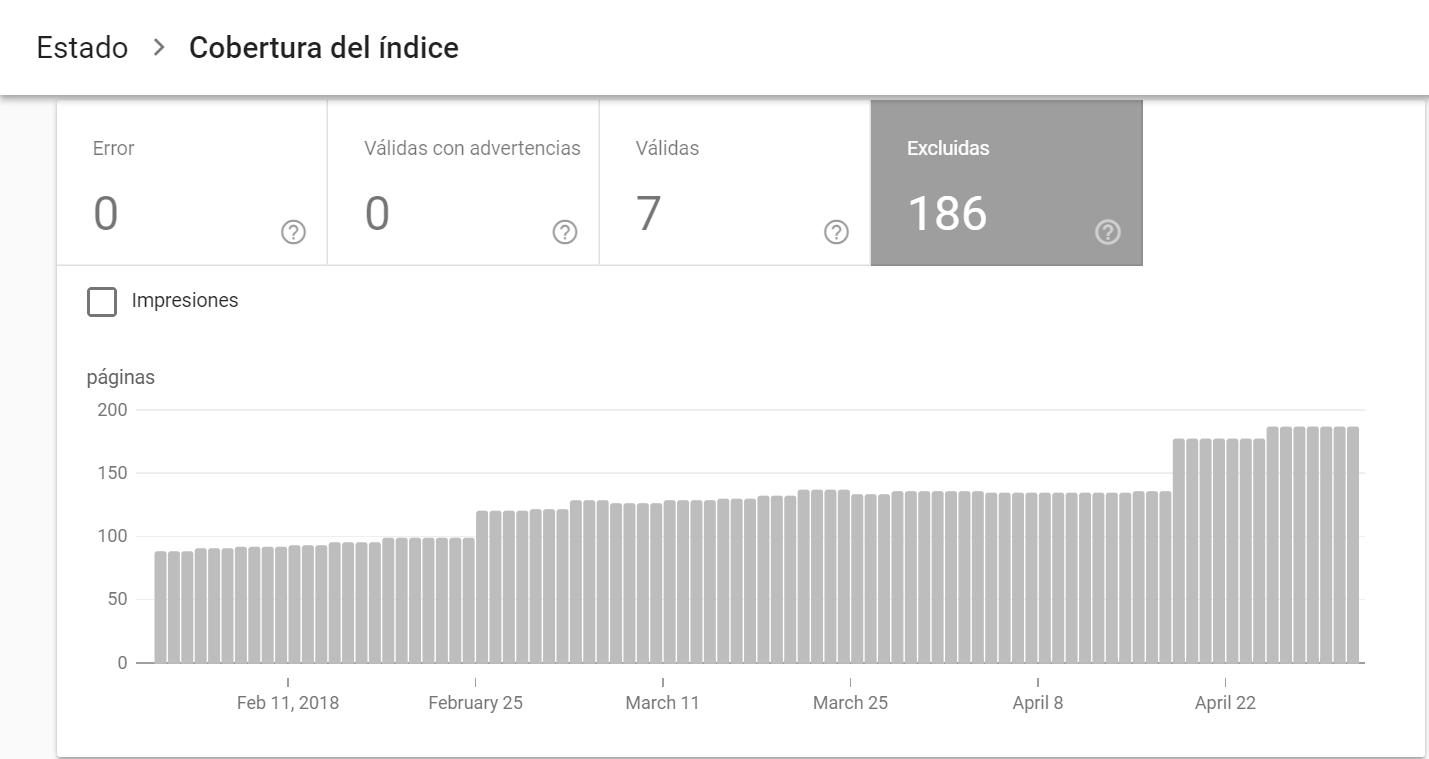
Estas páginas no se han incluido en el índice, y por tanto las debes revisar también, por algunos de los siguientes motivos:
- Hay una etiqueta “noindex” que impide su indexación. Lo normal es que esté correcta, porque las directivas “noindex” no se ponen solas (es algo que deberías haber hecho a conciencia). Pero no está de más que lo revises.
- Se ha bloqueado mediante una solicitud de retirada. Se trata de URLs que se han indexado y has pedido al Google que la elimine. Solamente se elimina temporalmente, pasado un tiempo volverá a ver si la puede indexar o no (si ya le has metido el noindex).
- Están bloqueadas a través del robots.txt a pesar de que se hayan encontrado enlaces hacia ellas.
- Googlebot no ha podido acceder al contenido por temas de seguridad (acceso no autorizado).
- Anomalía en el rastreo, que impide al robot cargar la página (suele ser error 404 o error 500). Puede ser algún archivo (ej. una imagen) cuya URL no se ha examinado correctamente y el robot es incapaz de cargarlo.
- Rastreada pero sin indexar. Páginas que el robot ha examinado, pero “no ha querido” indexar por el momento. Puedes solicitar la indexación aquí.
- Descubierta, pero sin indexar. Google sabe que existe esa página (ha encontrado un enlace a ella) pero no la ha podido examinar en ese momento y por tanto tampoco la ha podido indexar.
- Página canónica alternativa. Son páginas duplicadas, que tienen una etiqueta rel=canonical indicando cuál es la página correcta que se debe indexar.
- Página duplicada sin etiqueta canónica. Google las considera contenido duplicado y no tiene forma de saber cuál es el contenido correcto a indexar.
- Página duplicada que no es HTML. La URL corresponde a un documento cuya información es la misma que Google ya ha identificado e indexado anteriormente.
- Página canónica incorrecta para Google. Páginas indicadas como contenido canónico (el oficial a rastrear), pero que Google considera que no deberían serlo (cree que hay otra URL que refleja mejor ese contenido).
- Error 404. Páginas que el servidor no puede encontrar. En este caso el robot ha rastreado la página en algún momento, pero actualmente no se encuentra. Por lo que el robot dejará de rastrearla y mostrarla en los rankings.
Cómo actuar para solucionar los Problemas de Cobertura del índice
1. Revisa cada una de las filas de la tabla que muestra los motivos de cada estado.
Al hacer clic sobre cada fila verás un nueva tabla con ejemplos de los errores encontrados.
2. Revisa y soluciona cada uno de los errores
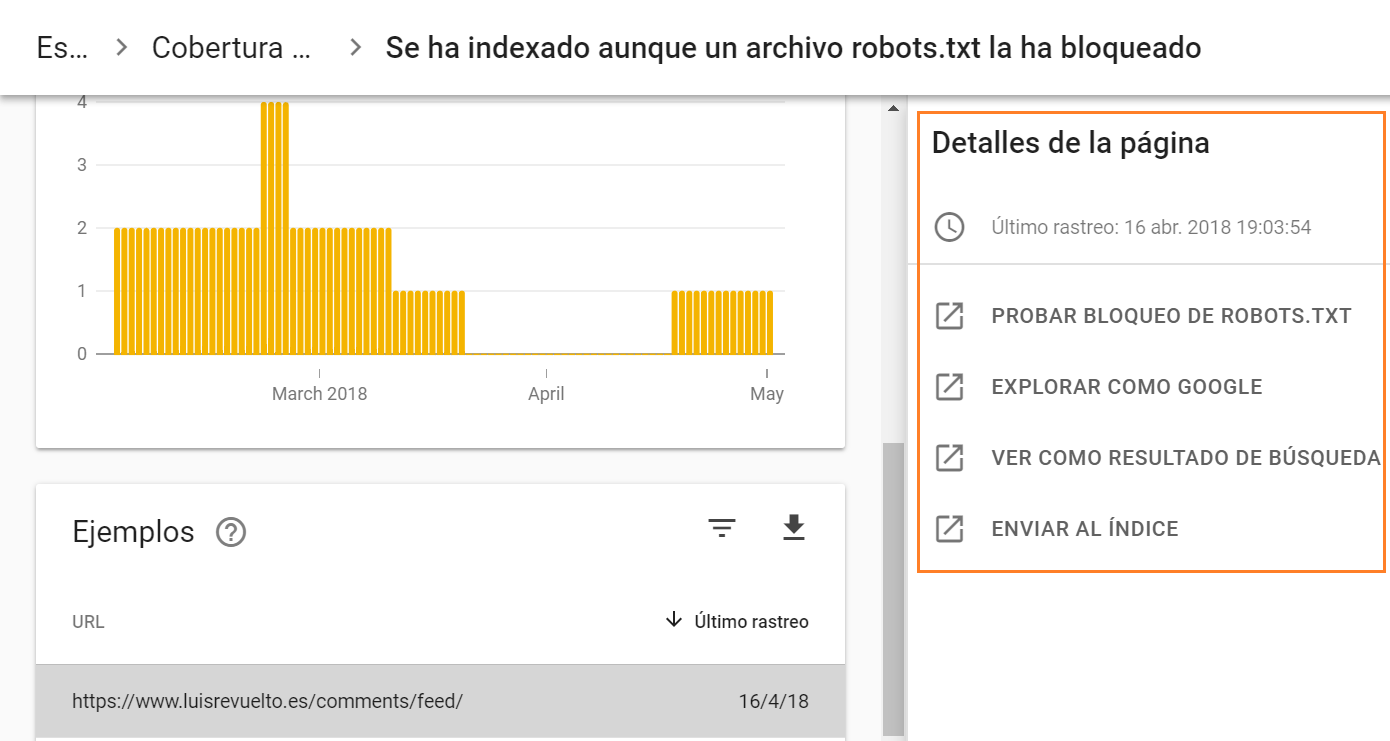
Al hacer clic sobre cada una de las filas se mostrará una nueva ventana con herramientas para validar y solucionar los errores.
Encontrarás un enlace a la herramienta Probador de Robots.txt. Por si la URL está bloqueada, para que veas en qué línea aparece la instrucción de bloqueo.
También un enlace al Fetch de Google para que veas cómo procesa Google esa URL. Por ejemplo, si se encuentra con una redirección.
Puedes ver más información sobre como indexa Google la URL con el comando “info:” + la URL correspondiente.
Y por último enviar directamente la URL al índice de Google si consideras que está correcta.
3. Solicita la validación
Si te has asegurado de que los errores están corregidos, puedes solicitar a Google que valide estos cambios. La propia herramienta te ofrece esta opción a través del informe.
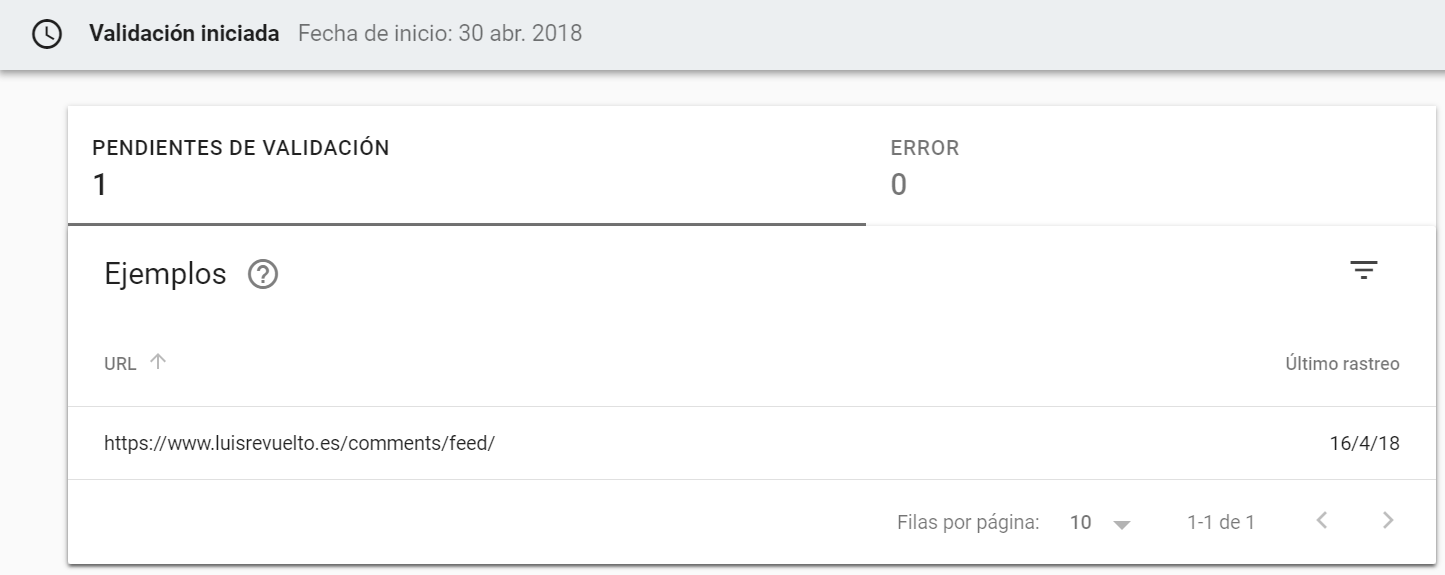
Te dejo el enlace a la ayuda de Google por si quieres profundizar un poco más sobre el tipo de error que te aparece y la solución recomendada por el propio buscador.
Conclusión: Atento a la Nueva Search Console
Aunque es una versión beta, a la que aún le falta añadir todas las funcionalidades de la actual Search Console, te recomiendo que empieces a utilizarla. Tienes muy información super valiosa sobre cómo está Google indexando tu sitio. Y puedes ver más datos sobre la analítica de búsqueda, por un período más amplio.
Iré ampliando información en esta entrada conforme vaya evolucionando la herramienta o cuando tengamos una versión estable.
¡Te veo en los comentarios!



Muy buena informacion…Aun sigo con la antigua versión pero parece quw ha llegado la hora del cambio. Un saludo.
¡Muchas gracias Manuel! Sí, de momento lo ideal es que utilices las 2 versiones. Porque en la nueva Search Console aún no han incluido el 90% del resto de funcionalidades de la versión antigua. Pero es posible que pronto lo hagan y merezca la pena cambiarse directamente a la nueva.
Un saludo.
Muchas gracias por la información, me salieron dos errores y con los cambios no sabia que tenia que hacer, ahora ya se de que va esto un poco gracias a ti.
Espero que pronto nos pongas más información.
Muchas gracias por tu comentario. Me alegro de que te haya sido útil la información. Haré más entradas sobre la Nueva Search Console.
Un saludo.
Muy buena información. El mes pasado me llego un email con problemas en el indice, por suerte pude solucionarlo mediante el archivo robots.txt. Muchas gracias por compartir.
Genial Nicolas. Me alegra mucho que pudieras solucionar y también que te haya gustado el artículo 🙂
Un saludo
Luis, en el primer sitemap que envié a Search Console tenía una serie de páginas con noindex. Posteriormente quité la metaequita y ahora ya son indexables para los buscadores.
¿Cómo soluciono el error en Search Console?
¡Hola!
¿Qué tipo de mensaje quieres solucionar? Imagino que te refieres a páginas que no deben ser indexadas pero ya lo están por Google y se encuentran bloqueadas en Robots.txt. Si es así, puedes quitar las líneas de bloqueo de robots.txt, al menos temporalmente y volver a colocar la metaetiqueta noindex.
Si tienes problemas me dices.
Un saludo
Yo ya estoy probando la nueva versión de Search Console casi de manera exclusiva, me parece mucho más facil para solicitar la indexación de páginas nuevas, antes tenías que eliminar el dominio, ahora con un copia pega esta arreglago
Hola José. Muchas gracias por tu comentario. La verdad es que la nueva versión es un gran avance para los SEO 😉
Un saludo
Hola Luis, muy interesante el post.
Te cuento, tengo un montón de excluidas por este motivo y no sé como solucionarlo.
Duplicada: Google ha elegido una versión canónica diferente a la del usuario.
Cambié el dominio de mi web, era planificatuvisita.com por cuentaunviaje.com, hice por tanto una redirección de un dominio a otro para no perder lo que pude posicionar.
Y tengo otra redirección para que siempre se acceda a las páginas por https.
Me sale ese error porque parece que google elegía la versión canónica por el protocolo http.
¿Sabes cómo puedo actuar?
Gracias!!
¡Hola Beatriz! Muchas gracias por tu comentario. Antes de nada una duda. ¿Estás revisando Search Console con la propiedad correcta? Es decir, actualmente tienes que estar viendo la propiedad https://cuentaunviaje.com/ no http://cuentaunviaje.com/ ni http://www.cuentaunviaje.com/ ni https://www.cuentaunviaje.com. ¿Puedes pasarme algún ejemplo de página que te haya excluido con ese motivo? Si quieres, también puedes contactarme utilizando los datos de la página de contacto 🙂
Un saludo
Hola Luis
¿Cómo diferenció entre una página que debe ir indexada y otra que me conviene que no lo esté (las producidas por tags por ejemplo)?
Saludos ☺️
Hola Luis me puse a leer tu artículo porque justamente he notado un cambio en el numero de visitas de mi blog educativo y ahora veo que tengo 5 mil y pico de paginas excluidas. Mi web es del dominio wordpress genmolecular.com
Yo creo que tambié pudo haber pasado que el año pasado cambié de tema, desde esa fecha el numero de visitas cada vez se reduce mas y mas y pensando en que tenía problemas con la carga de imágenes le puse un plugin que reduce el tamaño de imágenes, eso solucionó algunos problemas pero ahora generó otros Hay muchas con advertencias de que el tamaño es menor al recomendado y otras que no son válidas para nada. Este Blog fué una maravilla para mi pero ahora me está trayendo tantos problemas, yo lo hago por amor y dedicación a los demás y es gratuito pero no sé que hacer si pienso en entrar en mas de 5000 mil paginas para corregrir!! algun consejo? creo que no tengo un backup además (estoy jodi…) Gracias de antemano y re bien explicadopara los inexpertos como yo!!! Gracias
Hola Gabi,
Tienes que revisar al menos los ejemplos que te vienen en las páginas excluidas y pulsar inspeccionar URL, para tener una idea de cuál es el problema y poder corregirlo. Te advierto que tienes muchas URLs que no tienen prácticamente contenido (Thin Content), por ejemplo https://genmolecular.com/n/ y probablemente son las que te está excluyendo. Pueden tener un estado «Rastreada sin indexar» (si lleva mucho tiempo rastreada, es que no la piensa indexar por este motivo). En este tipo de URLs tienes dos opciones: meteler contenido o eliminarlas y mandar un código de error 410 para que las quite del índice. Y sí, parece que entre ellas, están algunas URLs de imágenes que deberían redireccionar a la URL de la imagen o al menos no indexarse. Te recomiendo que leas este artículo que escribí en el blog de Dean Romero, donde indico qué hacer con este problema: https://blogger3cero.com/guia-nueva-search-console/.
Por otro lado, te recomiendo también alojar la web en un hosting bueno, con tenga copias de seguridad tipo Siteground: https://www.siteground.es/go/hostingdominiosg. Cualquier duda coméntanos por aquí.
Un saludo
Hola Luis, en primer lugar muchas gracias y enhorabuena por el trabajo que haces, me ha surgido una duda a la que en un principio no le dí demasiada importancia.
Tengo un wordpress https://kokorofotografia.com/ de mi empresa que gestino yo mismo, como página de inicio tengo colocada https://kokorofotografia.com/fotografo-de-boda-en-granada esto me lo hace automático el wordpress.
Search Console me da la dirección( https://kokorofotografia.com/fotografo-de-boda-en-granada) excluida por Cobertura/Página con redirección y me dice que he seleccionado como canonica https://kokorofotografia.com/.
¿Debería de preocuparme o es normal?
Un saludo y gracias de antemano.
¡Hola Alvaro!
Veo que has aprovechado bien para colar un poco de publicidad para tu web :D. La duda que planteas en cualquier caso es muy interesante. Dado que en la URL de fotografo en granada no tienes contenido, es normal que te marque otra URL como canónica. Ya que el contenido de dicha página (cabecera, pie y poco más) es duplicado y se queda con el que considera más relevante. Lo que tienes que hacer es dotar a esa página de contenido original y diferente del resto de páginas.
Un saludo
Saludos, excelente articulo.
La nueva Search Console esta volviedo loco a medio mundo.
Te consulto lo siguiente:
1 – Cobertura: Rastreada: actualmente sin indexar – Fuente: Smartphones
Estado: Excluidas – Paginas afectadas 47 – Todas las paginas son del Feed
2 – Excluida por una etiqueta «noindex» – Fuente: Smartphones – Todas son categorias
Esto es un problema?
Hay que hacer algo al respecto?
Gracias
Hola Carlos
Simplemente revisa si esas URLs son páginas que realmente quieres que se indexen porque te interesan para SEO. Por ejemplo, las URLs del feed no hay que indexarlas, con lo que esas están ok. Las categorías no deberían llevar una etiqueta noindex (a no ser que sean categorías con 0 información que no te interesen por SEO), así que probablemente tengas configurado que no quieres que aparezcan en Google (¿utilizas Yoast?). Y las rastreadas sin indexar, suelen ser páginas que también tienen una etiqueta noindex. Revisa si le tienes configurado que no aparezcan en Google y si te interesa o no que aparezcan .
Un saludo
Hola que tal! Hace menos de una semana cree mi página web: y ahora me sale, en la sección de cobertura que todas mis páginas se encuentran descubiertas: actualmente sin indexar ¿Que debería hacer?
Hola Elías
¿Has copiado el contenido de otras webs? Es posible que te ocurra esto por tener contenido duplicado. Google estaría considerando irrelevante tu página para ese contenido. En ese caso, te recomiendo que reescribas el contenido de tu página y crees contenido 100% original.
Un saludo
Hola, Luis.
Recién cambiamos la estructura general de la web y hay bastantes (más de 2.000) URLs que se han quedado obsoletas. Ahora Google Search las detecta como «Anomalía de Rastreo», pero en realidad no pasa nada porque son URLs obsoletas y todas dan un error 404.
La pregunta es, merece la pena solicitar la retirada manual de contenido obsoleto de estas páginas (porque son bastantes) o puedo simplemente esperar que Google las retire automáticamente con el tiempo?
Gracias.
Hola Edu,
Si no tienes enlaces hacia esas 2000 URLs puedes esperar tranquilamente a que se vayan retirando poco a poco. Los errores 404 le indican a Google que no se encuentra disponible una URL concreta. Cuando trate de rastrearla varias veces y se encuentre un 404, la quitará del índice. Así que, no es necesario que vayas eliminando una a una si no tienes enlaces internos y/o externos hacia ellas.
Un saludo
Perfecto, muchas gracias por la información!